
- 00 开篇词 SRE是解决系统稳定性问题的灵丹妙药吗?.md
- 01 SRE迷思:无所不能的角色?还是运维的升级?.md
- 02 系统可用性:没有故障,系统就一定是稳定的吗?.md
- 03 SRE切入点:选择SLI,设定SLO.md
- 04 错误预算:达成稳定性目标的共识机制.md
- 05 案例:落地SLO时还需要考虑哪些因素?.md
- 06 故障发现:如何建设On-Call机制?.md
- 07 故障处理:一切以恢复业务为最高优先级.md
- 08 故障复盘:黄金三问与判定三原则.md
- 09 案例:互联网典型的SRE组织架构是怎样的?.md
- 10 经验:都有哪些高效的SRE组织协作机制?.md
- 答疑 没什么能阻挡你拓展边界的渴望.md
- 结束语 聊聊我的SRE落地心路历程.md
- 捐赠
03 SRE切入点:选择SLI,设定SLO
你好,我是赵成,欢迎回来。
还是先来复习下上节课讲的“系统可用性”的两种计算方式,一种是从故障角度出发,以时长维度对系统进行稳定性评估;另一种是从成功请求占比角度出发,以请求维度对系统进行稳定性评估。同时,我们还讲到,在SRE实践中,通常会选择第二种,也就是根据成功请求的比例来衡量稳定性:
Availability = Successful request / Total request
SRE强调的稳定性,一般不是看单次请求的成功与否,而是看整体情况,所以我们会把成功请求的占比设定为一个可以接受的目标,也就是我们常说的“3个9”或“4个9”这样的可量化的数字。
那么,这个“确定成功请求条件,设定达成占比目标”的过程,在SRE中就是设定稳定性衡量标准的SLI和SLO的过程。
具体来看下这两个概念。SLI,Service Level Indicator,服务等级指标,其实就是我们选择哪些指标来衡量我们的稳定性。而SLO,Service Level Objective,服务等级目标,指的就是我们设定的稳定性目标,比如“几个9”这样的目标。
SLI和SLO这两个概念你一定要牢牢记住,接下来我们会反复讲到它们,因为落地SRE的第一步其实就是“选择合适的SLI,设定对应的SLO”。
好,那我们就正式开始今天的内容。我会带你彻底理解SLI和SLO这两个概念,并掌握识别SLI、设定SLO的具体方法。
SLI和SLO到底是啥?
SLI和SLO这两个概念比较有意思,看字面意思好像就已经很明白了,但是呢,仔细一想,你会发现它们很抽象。SLI和SLO指的到底是啥呢?
接下来我给你讲一个具体的例子,讲完后,你肯定就能理解了。
我们以电商交易系统中的一个核心应用“购物车”为例,给它取名叫做trade_cart。trade_cart是以请求维度来衡量稳定性的,也就是说单次请求如果返回的是非5xx的状态码,我们认为该次请求是成功的;如果返回的是5xx状态码,如我们常见的502或503,我们就判断这次请求是失败的。
但是,这个状态码只能标识单次请求的场景。我们之前讲过,单次的异常与否并不能代表这个应用是否稳定,所以,我们就要看在一个周期内,所有调用次数的成功率是多少,以此来确定它是否稳定。比如我们给这个“状态码返回为非5xx的比例”设定一个目标,如果大于等于99.95%,我们就认为这个应用是稳定的。
在SRE实践中,我们用SLI和SLO来描述。“状态码为非5xx的比例”就是SLI,“大于等于99.95%”就是SLO。说得更直接一点,SLO是SLI要达成的目标。
通过这个例子,你现在是不是已经理解了这两个概念呢。SLI就是我们要监控的指标,SLO就是这个指标对应的目标。
好,那接下来我们要解决的问题就很具体了。我们应该选择哪些指标来监控系统的稳定性?指标选好后,对应地怎么定它的目标呢?下面咱们就一一来探索。
系统运行状态指标那么多,哪些适合SLI?
我们先来讨论怎么选择SLI。要回答怎么选择这个问题,我们得先来看看都有哪些可供选择的指标。
在下面这张图中,我列举了系统中常见的监控指标。-
 -
这些指标是不是都很熟悉?那该怎么选呢?好像每一个指标都很重要啊!
-
这些指标是不是都很熟悉?那该怎么选呢?好像每一个指标都很重要啊!
确实,这些指标都很重要。我们可以通过问自己两个问题来选择。
第一个问题:我要衡量谁的稳定性? 也就是先找到稳定性的主体。主体确定后,我们继续问第二问题:这个指标能够标识这个实例是否稳定吗? 一般来说,这两个问题解决了,SLI指标也就确认了。
从我的经验来看,给指标分层非常关键。就像上图那样分层后,再看稳定性主体是属于哪一层的,就可以在这一层里选择适合的指标。但是,你要注意,即便都是应用层的,针对具体的主体,这一层的指标也不是每一个都适合。
根据这几年的实践经验,我总结了选择SLI指标的两大原则。
原则一:选择能够标识一个主体是否稳定的指标,如果不是这个主体本身的指标,或者不能标识主体稳定性的,就要排除在外。
原则二:针对电商这类有用户界面的业务系统,优先选择与用户体验强相关或用户可以明显感知的指标。
还拿我们上面trade_cart的例子来说,主体确定了,就是trade_cart,应用层面的,请求返回状态码和时延就是很好的指标,再来检查下它们能否标识的trade_cart稳定性,毫无疑问,这两个指标都可以,那么请求返回状态码和时延就可以作为trade_cart稳定性的SLI指标。
我们换一个指标,CPU的使用率这个指标适合吗?根据我们刚才说的原则,既然我们关注的是trade_cart的运行状况,而CPU是系统层的指标,所以,在选择应用层SLI的指标时,自然会把CPU排除掉。
你可能会说,这样是不是太武断了呀?
我们简单来分析下。假设CPU使用率达到了95%,但是只要CPU处理能力足够,状态码成功率可能还是保持在4个9,时延还是在80ms以内,用户体验没有受到影响。另外一种情况,假设CPU使用率只有10%,但是可能因为网络超时或中断,导致大量的请求失败,甚至是时延飙升,购物车这个应用的运行状态也不一定是正常的。所以结论就是,CPU使用率不管是10%还是95%,都不能直接反映trade_cart运行是正常还是异常,不适合作为trade_cart这样的应用运行稳定性的SLI指标。
讲到这里,你可能会问,哎呀,你说的这两个原则我理解了,分层也大概能做到,但是我还是需要做很多详细的分析才能选择出SLI指标,有没有什么更便捷、更快速的方法来帮助我选择啊?
嗯,不要着急,还真有这样一套方法。怎么选SLI,我们可以直接借鉴Google的方法:VALET。
快速识别SLI指标的方法:VALET
VALET是5个单词的首字母,分别是Volume、Availability、Latency、Error和Ticket。这5个单词就是我们选择SLI指标的5个维度。我们还是结合trade_cart这个例子,一起看一下每个维度具体是什么。
Volume-容量
Volume(容量)是指服务承诺的最大容量是多少。比如,一个应用集群的QPS、TPS、会话数以及连接数等等,如果我们对日常设定一个目标,就是日常的容量SLO,对双11这样的大促设定一个目标,就是大促SLO。对于数据平台,我们要看它的吞吐能力,比如每小时能处理的记录数或任务数。
Availablity-可用性
Availablity(可用性)代表服务是否正常。比如,我们前面介绍到的请求调用的非5xx状态码成功率,就可以归于可用性。对于数据平台,我们就看任务的执行成功情况,这个也可以根据不同的任务执行状态码来归类。
Latency-时延
Latency(时延)是说响应是否足够快。这是一个会直接影响用户访问体验的指标。对于任务类的作业,我们会看每个任务是否在规定时间内完成了。
讲到这里,我要延伸下,因为通常对于时延这个指标,我们不会直接做所有请求时延的平均,因为整个时延的分布也符合正态分布,所以通常会以类似“90%请求的时延 <= 80ms,或者95%请求的时延 <=120ms ”这样的方式来设定时延SLO,熟悉数理统计的同学应该知道,这个90%或95%我们称之为置信区间。
因为不排除很多请求从业务逻辑层面是不成功的,这时业务逻辑的处理时长就会非常短(可能10ms),或者出现404这样的状态码(可能就1ms)。从可用性来讲,这些请求也算成功,但是这样的请求会拉低整个均值。
同时,也会出现另一种极端情况,就是某几次请求因为各种原因,导致时延高了,到了500ms,但是因为次数所占比例较低,数据被平均掉了,单纯从平均值来看是没有异常的。但是从实际情况看,有少部分用户的体验其实已经非常糟糕了。所以,为了识别出这种情况,我们就要设定不同的置信区间来找出这样的用户占比,有针对性地解决。
Errors-错误率
错误率有多少?这里除了5xx之外,我们还可以把4xx列进来,因为前面我们的服务可用性不错,但是从业务和体验角度,4xx太多,用户也是不能接受的。
或者可以增加一些自定义的状态码,看哪些状态是对业务有损的,比如某些热门商品总是缺货,用户登录验证码总是输入错误,这些虽不是系统错误,但从业务角度来看,对用户的体验影响还是比较大的。
Tickets-人工介入
是否需要人工介入?如果一项工作或任务需要人工介入,那说明一定是低效或有问题的。举一个我们常见的场景,数据任务跑失败了,但是无法自动恢复,这时就要人工介入恢复;或者超时了,也需要人工介入,来中断任务、重启拉起来跑等等。
Tickets的SLO可以想象成它的中文含义:门票。一个周期内,门票数量是固定的,比如每月20张,每次人工介入,就消耗一张,如果消耗完了,还需要人工介入,那就是不达标了。
这里我给出一个Google提供的,针对类似于我们trade_cart的一个应用服务,基于VALET设计出来的SLO的Dashboard样例,结合上面我们介绍的部分,就一目了然了。-
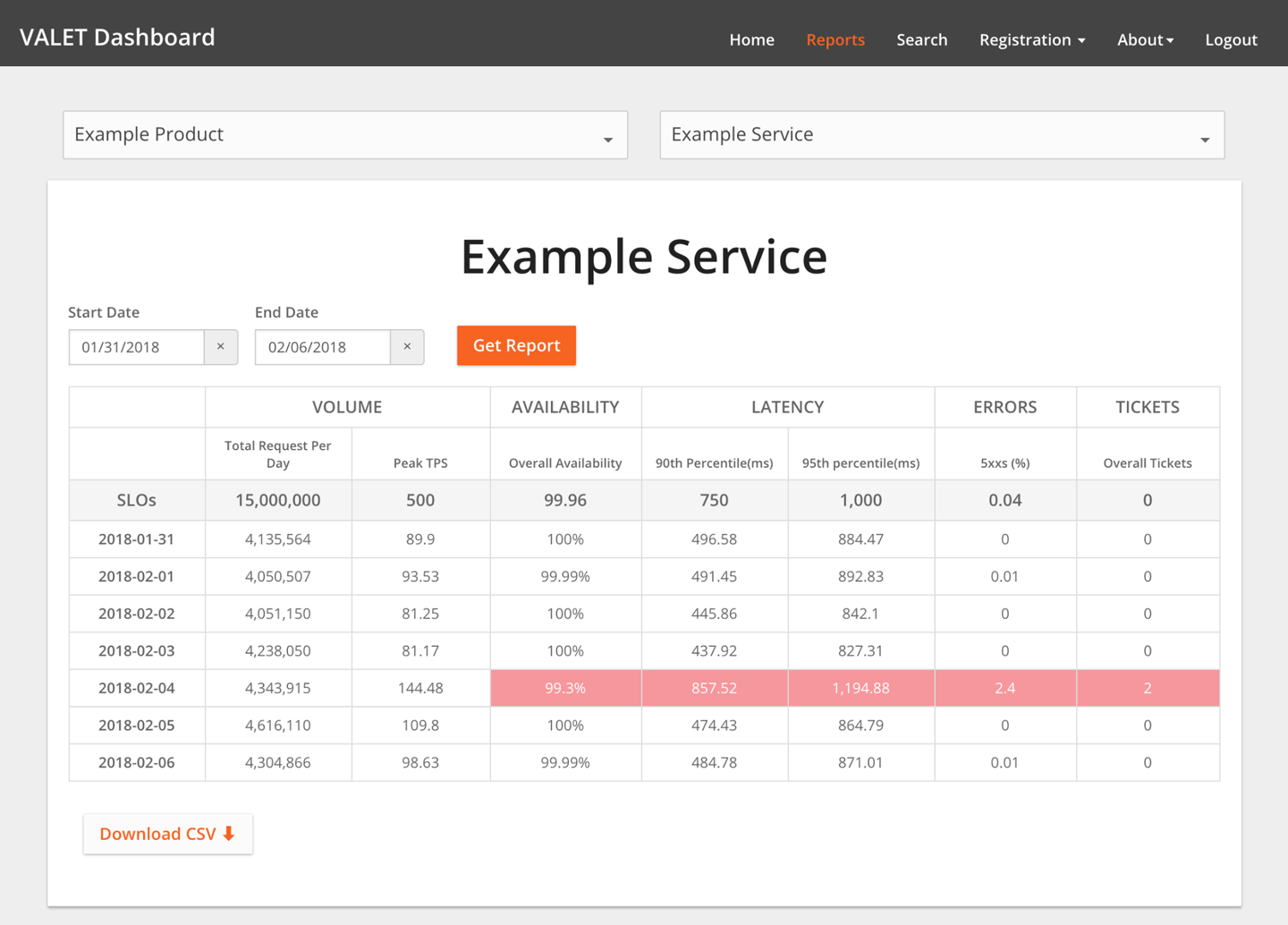 -
好,VALET我们就讲完了,怎么选SLI指标,你是不是一下子就清楚了。可以说,这是一个我们可以直接复用的工具。上面Google的这张SLO样例图,建议你多看几遍,看到时候,对比思考下自己系统的情况。
-
好,VALET我们就讲完了,怎么选SLI指标,你是不是一下子就清楚了。可以说,这是一个我们可以直接复用的工具。上面Google的这张SLO样例图,建议你多看几遍,看到时候,对比思考下自己系统的情况。
如何通过SLO计算可用性?
到这里,我们已经能够根据自己想要保障稳定性的主体,来选择合适的SLI指标了,也知道SLO就是对应SLI要实现的目标,比如“几个9”。
但是,我们前面讲到了系统可用性:
Availability = Successful request / Total request
然后又深入到了提炼具体的SLI,以及设定对应的SLO,那这两者之间是什么关系呢?也就是通过SLO应该怎么去计算我们的系统可用性的呢?这就涉及到系统整体可用性的两种计算方式。
第一种,直接根据成功的定义来计算。- 也就是我们前面定义一个请求的返回状态码必须是非5xx才算成功,同时时延还要低于80ms,同时满足这两个条件,我们才算是成功的,也就是纳入上述公式中Successful request的统计中,用公式来表示:
Successful = (状态码非5xx) & (时延 <= 80ms)
如果还有其它条件,直接在后面增加做综合判定。
但是,这种计算方式存在的问题就是,对单次请求的成功与否的判定太过死板,容易错杀误判。比如我们前面讲对于时延,我们一般会设定置信区间,比如90%时延小于等于200ms这样的场景,用这种方式就很难体现出来。而且,对于状态码成功率和时延成功率的容忍度,通常也是也不一样的,通过这种方式就不够准确。所以,我们就会采取第二种方式。
第二种方式,SLO方式计算。
我们前面讲时延时讲过以下几个SLO,这时我们设定稳定性的时候,就需要把公式计算方式灵活调整定义一下了。
- SLO1:99.95% 状态码成功率
- SLO2:90% Latency <= 80ms
- SLO3:99% Latency <= 200ms
直接用公式表示:
Availability = SLO1 & SLO2 & SLO3
只有当这个三个SLO同时达标时,整个系统的稳定性才算达标,有一个不达标就不算达标,这样就可以很好地将SLO设定的合理性与最终可用性结合了起来。所以,通常在SRE实践中,我们通常会采用这种设定方式。
如果是这样,第一种方式是不是就没有用途了呢?当然不是。第一种计算方式也会有它特有的应用场景,它通常会被利用在第三方提供的服务承诺中,也就是SLA( Service Level Agreement)。因为对于第三方提供商来说,比如云厂商,它们要面对的客户群体是非常大的,所以很难跟每一家客户都去制定像SLO这么细粒度稳定性目标,而且每家客户对稳定性的要求和感知也不同,就没法统一。
这种情况下,反而是第一种计算方式是相对简单直接的,但是这样也决定了SLA的承诺相比SLO肯定也相对比较宽松,因为SLA是商业服务承诺,如果达不成是要进行赔偿的。关于SLA,最直接的参考资料,就是各个公有云厂商在官网公开的信息资料,你可以找到这些资料,作为自己的一个补充学习。
总结
讲到这里,怎么选择SLI指标、如何制定SLO目标,我们就介绍完了。你需要掌握下面三个重点。
- 对系统相关指标要分层,识别出我们要保障稳定性的主体(系统、业务或应用)是什么,然后基于这个主体来选择合适的SLI指标。
- 不是所有的指标都是适合做SLI指标,它一定要能够直接体现和反映主体的稳定性状态。可以优先选择用户或使用者能感受到的体验类指标,比如时延、可用性、错误率等。
- 掌握VALET方法,快速选择SLI指标。
思考题
最后,给你留一个思考题。
下面我给出一个Google的SLI和SLO设定标准示例,内容很直观,需要你认真研究一下这个文档,结合今天我们所讲的内容,请你尝试按照Google提供的规范格式,制定一个自己所负责系统的SLO。
Google的SLI和SLO设定模板链接:https://landing.google.com/sre/workbook/chapters/slo-document
另外,对今天的内容如果你还有什么疑惑,都可以在留言区提问,也欢迎你把今天的内容分享给身边的朋友,和他一起学习讨论。
我是赵成,我们下节课见。
© 2019 - 2023 Liangliang Lee. Powered by gin and hexo-theme-book.